Context engineering is the “art and science of filling the context window with just the right information” for an AI agent[1][2]. In practice, an agent’s prompt context includes the system/user instructions, conversation history (short-term memory), any retrieved knowledge or tool outputs, and output schemas[3][4]. Rather than a single static prompt, context engineering treats prompt construction as a dynamic pipeline: selecting and curating all relevant inputs (e.g. user query, domain facts, tools, memories) so the LLM has the precise data and instructions needed.
Effective context engineering is critical for reliability and grounded reasoning. As one engineer put it, “most agent failures are not model failures… they are context failures”[5]. Feeding too much irrelevant context can confuse the model; too little can lead to hallucination or omission. Enterprise agents often draw on large, evolving data sources (ERP/CRM systems, knowledge bases, code libraries, etc.), so context must be carefully assembled to remain accurate and up-to-date[6][7]. In the enterprise setting, context engineering often involves linking the agent to structured data (e.g. databases or data lakes) and domain knowledge (e.g. ontologies for SAP or Salesforce), then retrieving only the relevant pieces per request[7][8].
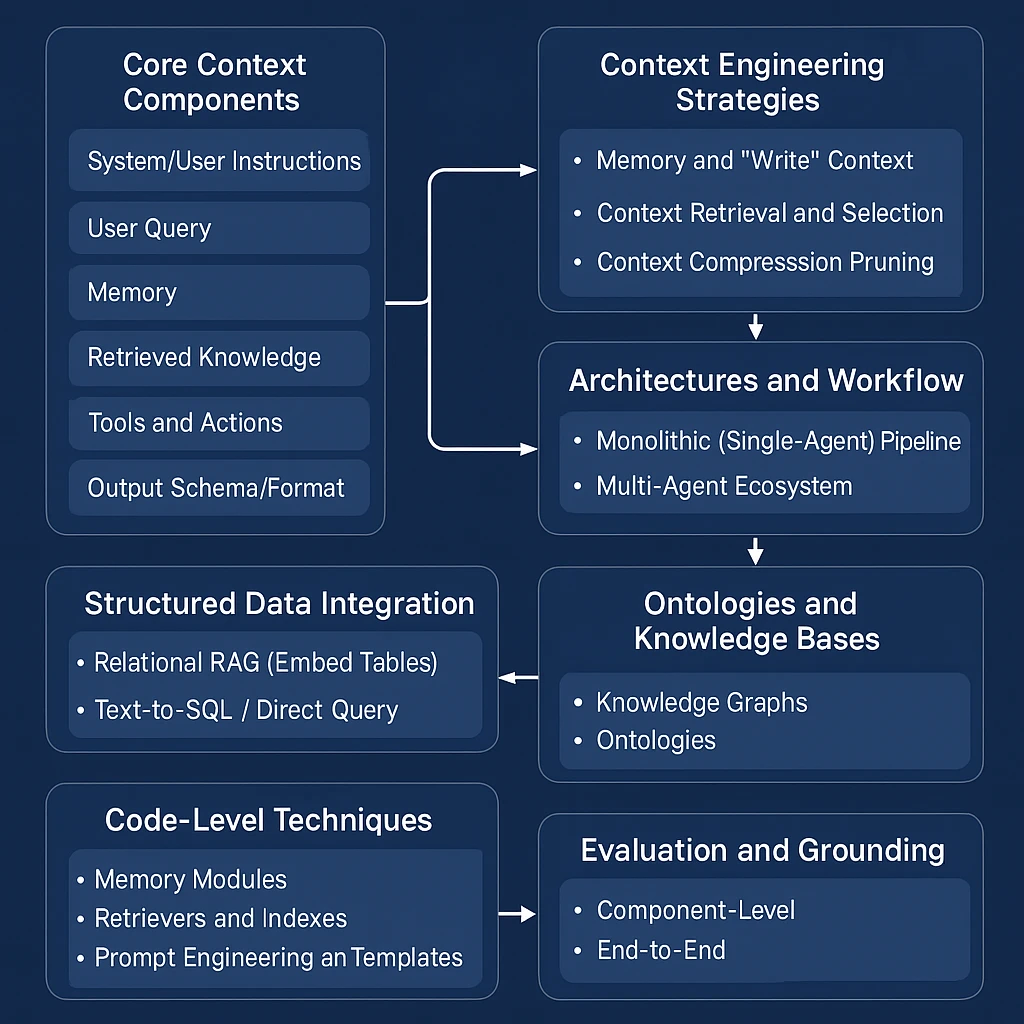
Core Context Components
A typical LLM-agent context may include: – System/user instructions: high-level goals, role definitions, business rules or policies to guide behavior.
– User query: the current request or question.
– Memory: Short-term (recent dialogue) and long-term facts (user preferences, past actions) that the agent stored. Long-term memory is often kept in vector stores or databases so it can be retrieved as needed[9][10].
– Retrieved knowledge: Externally fetched data from documents, databases, or APIs. This is usually done via RAG (Retrieval-Augmented Generation), where the system retrieves relevant facts or documents to ground the answer[11][12].
– Tools and actions: Descriptions of available functions or APIs (e.g. a SQL query tool, a pricing API) and their outputs. The agent can call these tools during reasoning; their descriptions and results are also context[7][13].
– Output schema/format: If the agent’s response must follow a structured format (JSON fields, tables), that schema itself is part of the context to guide the LLM’s output[14][15].
By curating these components for each step, the agent “sees” exactly the information it needs. For example, a sales-assistant agent given a query “give me last quarter’s sales by product” would have: system instructions to behave as a sales analyst, the user query, short-term chat history, the company’s products and sales data (retrieved via SQL or RAG), and a JSON schema specifying {product:…, sales:…}. With that rich context, the LLM can respond accurately and take actions (e.g. generate a report) rather than guessing or hallucinating.
Context Engineering Strategies
Context engineering methods generally fall into several categories: writing/persisting context, selecting/retrieving relevant context, compressing or pruning context, and isolating context (often via multi-agent design)[16][17]. These techniques ensure that at every step, the agent’s prompt window contains just the most useful information.
- Memory and “Write” Context: Agents can save useful facts outside the immediate context (“scratchpad” or long-term memory) for later use[18][10]. For example, an agent might summarize each step of reasoning into a memory store. This can be as simple as appending to a file or as sophisticated as a vector database of embeddings. Long-term memory allows the agent to recall past user interactions or learned knowledge across sessions[9][19]. In practice, frameworks like LangChain’s state object or LlamaIndex’s memory blocks let developers configure what information to persist. For instance, Palantir’s Customer Service Engine (CSE) stores user feedback as embeddings in its vector store, feeding it back as context so agents learn from mistakes[10].
- Context Retrieval and Selection: Rather than giving the LLM all knowledge at once, agents retrieve only task-relevant data. This often uses RAG techniques: documents or data chunks are embedded in a vector store, then at query time the user query is also embedded and a similarity search retrieves the top relevant chunks[20][12]. The retrieved text is then inserted into the LLM prompt as context. This ensures the model’s answer is grounded in real data. For structured enterprise data, similar ideas apply: rows or records from a database can be converted to text/embeddings (Relational RAG) and retrieved[21][22]. In addition to document retrieval, agents also select which memories or tools to include. A good memory system will search past interactions for relevant facts (e.g. “Has this customer reported issues before?”) using embedding search or indexes[23]. Likewise, if many tools/APIs are available, agents may retrieve only the subset whose descriptions best match the query to avoid confusion[24].
- Context Compression and Pruning: Because context windows are limited, agents must often condense information. Common techniques include summarization (using an LLM to distill long chat histories or search results) and truncation heuristics. For example, after many turns an agent might auto-summarize prior dialogue to keep the prompt short[25][26]. Context “trimming” might drop older or less-relevant messages (for instance, deleting parts of history or overlapping RAG chunks)[26]. Some systems apply hierarchical summarization or fine-tuned pruners to keep only the crucial points in context. In enterprise flows, this might mean summarizing a long internal report or condensing a log of customer interactions before appending it to the prompt.
- Context Isolation (Multi-Agent Decomposition): A powerful strategy is to break complex tasks into sub-tasks, each handled by a specialized agent with its own (smaller) context. For instance, one agent could classify a customer query (a “router” agent) and then invoke a specialized “sales data” agent or “technical support” agent depending on type[27][28]. This isolates contexts: the sales agent need only customer and inventory context, while the support agent has product manuals and ticket history. Multi-agent systems allow parallel reasoning and reduce context competition. Anthropic found that many isolated sub-agents each with focused context often outperform a single agent handling everything[29]. Salesforce likewise advocates multi-agent “Agentforce” designs for scalability and modularity[30]. In practice, orchestrators or routers direct queries to the right agents, and agents may in turn call tools (APIs or databases) to gather structured data. This decomposition also supports guardrails or verification agents that check answers for compliance[31].
Architectures and Workflow
At the system level, context engineering shapes the overall architecture of the LLM agent system. Two common patterns are:
- Monolithic (Single-Agent) Pipeline: The simplest design is a single agent that handles the whole task. It may sequentially retrieve data, call tools, and answer. For example, a chatbot that takes a question, runs RAG over a document store, and generates a response is a single-agent pipeline. This is easy to prototype but can hit context limits and is less flexible for very complex tasks.
- Multi-Agent Ecosystem: Here, multiple specialized agents collaborate under a control framework[27][30]. For example, an enterprise “customer service engine” might have one agent for invoice inquiries, another for inventory lookup, etc. An orchestration layer (or “router” agent) directs queries to the right sub-agent. Each agent can call its own tools (databases, APIs) and use tailored prompts. This modular architecture mirrors microservices: each component is decoupled, can be developed/tested in isolation, and scaled independently[32][30]. Salesforce’s Agentforce framework exemplifies this, defining protocols like a Model Context Protocol to feed data to agents and an Agent-to-Agent protocol for inter-agent calls[33]. The benefit is clear: a failure in one sub-agent doesn’t break the whole system, and new agents (or data sources) can be added without re-engineering the existing setup[27][30].
Tool and API integration is also central to architecture. Agents often call deterministic tools for tasks an LLM is weak at (e.g. math, database queries, or proprietary APIs). Common examples include a search API, a SQL query tool, or domain-specific functions (e.g. compute shipping ETA). Each tool has an input/output schema that is provided to the model as part of context, and the model learns to invoke tools via function-calling or special prompts[34][35]. Frameworks like LangChain or LlamaIndex help wire up these calls: you bind external functions as “tools” and the LLM can select and call them during reasoning[35]. In enterprise deployments, connectors to systems like SAP, Salesforce, or proprietary APIs serve as tools. For instance, Palantir’s CSE used tools to query SAP/ERP systems and UPS APIs, and incorporated about 50 such domain-specific tools into their agent platform[7][36]. These tools become part of the context pipeline: the agent’s reasoning loop reads tool outputs (e.g. fetched invoice data) and integrates them into the prompt for the next step.
Knowledge Graphs and Ontologies: Beyond plain text, many enterprise systems build structured ontologies or knowledge graphs to enrich context. For example, Palantir designed an Ontology (a digital twin of the organization) that encodes entities (customers, products, orders) and their relationships. The agents “hydrate” this ontology with data from SAP, Salesforce, etc., and then query it as needed[7][8]. This gives agents up-to-date, semantically rich context. Similarly, GraphRAG approaches (e.g. Neo4j’s GraphRAG) store data as a graph so that multi-hop relationships can be retrieved and explained[37][38]. In practice, an agent might combine text RAG (e.g. product manuals) with graph queries (e.g. traverse supplier–product relationships) to fully answer complex enterprise questions. Knowledge graphs also enable “explainable” reasoning: the chain of nodes/edges leading to an answer can be traced and audited. Thus, integrating an ontology or graph into the agent context provides structured semantics that mere text vectors lack.
Integrating Structured Data (Databases, Spark, etc.)
Enterprise agents often need to access structured tabular data (e.g. SQL databases, Spark dataframes). There are two main approaches to context-engineer these:
- Relational RAG (Embed Tables): Here, rows or records are transformed into text or embeddings and stored in a vector index[39][40]. For example, each database row (or joined row) can be converted to a JSON/string and embedded with a large model. An agent then embeds the user query and performs a nearest-neighbor search to retrieve the most relevant records. The retrieved data (often a few rows or summaries) are fed into the prompt. This allows natural-language queries (“What was Acme’s revenue last quarter?”) to match semantically even if schema terms differ. The retrieved records guarantee the answer is grounded in actual data[22][12]. The Akira.ai platform outlines exactly this flow: a Schema Reader ingests DB structure, an Embedding agent converts rows to vectors, and a Query agent retrieves similar rows for the LLM to answer[39][40]. The benefit is flexibility (no need to craft SQL), but it requires up-front embedding of large tables and careful chunking.
- Text-to-SQL / Direct Query: An alternative (and often simpler) method is to maintain a queryable DB and use the LLM to generate SQL. In this architecture, the agent uses a tool that runs SQL. The LLM’s prompt includes the database schema (tables/columns) and possibly some examples; the user question is turned into a SQL query which the tool executes to get the answer. This avoids RAG’s chunking and vector search entirely, ensuring exact results from the source. As some engineers note, a clean structured database plus a text-to-SQL agent can yield precise, reliable answers without vector fuzziness[41][42]. For unstructured data (PDFs, logs), one can first use parsers (like LlamaParse) to tabulate the data, then load it into SQL. Cloud providers even offer enterprise-grade NL-to-SQL services that scale to big data. The tradeoff is that text-to-SQL requires a well-defined schema and may struggle with vague queries, whereas RAG can handle more free-form document queries. In practice, many agents use hybrid approaches: e.g. for highly structured queries (retrieving specific records) use SQL, and for contextual information use RAG from documents or knowledge bases.
In either case, the system architecture must include ETL pipelines or connectors. Xenoss emphasizes ingesting and chunking enterprise documents into a vector store (for Vanilla RAG)[20][12]. Spark or similar engines often handle large-scale data preprocessing (Uber’s knowledge copilot used Spark for ETL on internal docs[43]). For real-time data (e.g. up-to-the-minute inventory), agents might call databases or streaming queries via tools. Importantly, grounding on fresh data is critical: “if an AI assistant misreports a revenue figure or misinterprets a filter, the mistake is obvious and costly”[44]. Thus context engineering must include data validation, filtering PII, and caching or re-indexing when source data changes, as recommended by enterprise best practices[45][46].
Ontologies, Knowledge Bases, and Semantic Models
To enrich context beyond raw text, enterprises often build knowledge graphs or ontologies of their domain. These formal models encode key entities (e.g. Customers, Orders, Products) and their attributes/relations. Agents can query these structures to get precise context. For example, Palantir’s CSE uses an ontology that the agent’s logic layer can query for “kinetic elements” (functions and models) and “semantic elements” (entities and properties)[47]. The ontology serves as a digital twin, and agents are “guardrailed” to only output information consistent with it[47]. When the partner company’s data (SAP, Salesforce, etc.) is loaded into this ontology, all agents can leverage it for up-to-date context[7].
Knowledge graphs similarly allow agents to do complex relational reasoning. As Neo4j points out, GraphRAG lets agents ask multi-hop questions (e.g. “Which suppliers related to product X saw increased orders?”) by traversing the graph[37]. In contrast to flat RAG, a graph-based context means the agent can retrieve exact nodes and their relationships. This is especially valuable for enterprise queries that cross-cut data silos. Integrating structured data into a graph (or ontology with rules) effectively creates a logical model that the agent can use for reasoning, not just text lookup. In summary, semantic models (ontologies, graphs) in the context pipeline provide richer, connected knowledge than text alone, making enterprise agents more robust and explainable.
Code-Level Techniques and Frameworks
At the implementation level, many libraries and patterns have emerged:
- Memory Modules: Libraries like LangChain’s Memory classes or LlamaIndex’s memory blocks let you persist and retrieve information. You define schemas (e.g. a user profile or rule set) to store in memory, which agents can query or update[19][48]. Checkpointing state across agent steps (e.g. LangGraph’s state object) acts as a scratchpad[49][50]. Long-term memory often uses vector databases (Pinecone, Weaviate) or databases with semantic indexing.
- Retrievers and Indexes: For RAG, code must chunk and embed data. Tools like LangChain, LlamaIndex, or Hugging Face’s datasets handle document splitting. Embedding models (OpenAI, LLaMA, etc.) convert chunks to vectors, which are stored in a vector DB. The agent’s code then takes a query, embeds it, runs a similarity search (using HNSW, IVF indexes, etc.), and fetches the top-k chunks. Some advanced techniques include hybrid retrieval (combining dense and BM25 search) and reranking (passing candidates through another model)[51].
- Prompt Engineering and Templates: Context engineering also involves writing effective prompts. Even as a system, the initial “system prompt” or instruction template must be clear. Techniques like few-shot examples or output-schemas are coded into the prompt. Some systems (e.g. LlamaExtract) use structured-output prompts to extract relevant fields from text, so the agent receives a concise structured summary instead of raw text[52][53].
- Tool Integration Code: Modern LLM APIs often support native function calling (OpenAI plugins, Azure AI, etc.). With LangChain or similar frameworks, one “binds” a Python function as a tool. The LLM sees a description of the function (its name and JSON schema inputs) in the prompt, and can output a special format indicating it wants to call that function. The agent runtime then executes it and feeds the JSON result back into the prompt[35]. This pattern is used for database queries (a SQL tool), web searches, math functions, etc. Enterprises often implement their internal APIs (ERP queries, inventory lookup) behind such function tools.
- Workflow Orchestration: Beyond individual LLM calls, agent workflows can be coded. Platforms like LangSmith or LlamaIndex Workflows allow you to define sequences of steps: e.g. Step1: retrieve user profile, Step2: retrieve records, Step3: summarize findings. At each step you control which context is passed. This workflow engineering ensures that complex tasks are broken into manageable LLM calls, preventing any one prompt from overflowing with context[54][55]. It also lets you insert validation or branching logic outside the LLM, improving reliability.
Evaluation and Grounding
Finally, rigorous evaluation and grounding are essential. Enterprise agents must be auditable and correct, not just plausible. Since agents involve multi-step workflows, evaluation occurs at two levels[56]:
- Component-Level Evaluation: Test each piece separately. For example, measure the accuracy of the SQL queries or retrievals the agent generates (tool correctness), the precision/recall of RAG retrieval, and the fidelity of any generated summaries. Tools like DeepEval or LangSmith can run automated tests on agent traces to spot faulty tool calls or context retrievals[57][58].
- End-to-End Evaluation: Feed sample inputs and check whether the agent’s final answers/tasks are correct. Metrics can include task completion rate, factual accuracy, latency, and compliance with requirements. For enterprise use, one might compare agent answers to ground-truth data (e.g. did it fetch the correct invoice amounts?) and measure user satisfaction or error rates. Continuous feedback loops are important: Palantir, for example, iteratively evaluated CSE’s responses with domain experts and added guardrails when errors were found[7][10].
Grounding means tying the agent’s output to real data sources. By construction, context engineering (via RAG or database queries) grounds the LLM’s generation. Techniques like source attribution (providing citations), confidence scoring, and external fact-checking can further enforce trust[45][41]. In enterprise settings, stringent data governance is needed: sensitive data is filtered out of context, and access controls ensure the agent only sees appropriate information[59][60].
In summary, context engineering for LLM agents is a rich, multi-faceted discipline. It combines prompt and memory design, smart retrieval of enterprise data, architectural modularity (ontology, multi-agents), and rigorous evaluation. By assembling context through pipelines of tools, memories, and workflows, an LLM agent can effectively harness large internal knowledge (from SAP, Salesforce, custom databases, etc.) and deliver grounded, enterprise-grade intelligence[7][61]. This often involves building knowledge bases (vector or graph), creating ontologies as “digital twins,” and decomposing problems across specialized agents or subprocesses[27][30]. The result is an AI system that behaves less like a vague chatbot and more like a precise, data-driven enterprise assistant.
Sources: Concepts and patterns above are drawn from recent literature and case studies on LLM agents and context engineering[1][11][7][6][27][61][62]. Each citation links to a specific discussion of the technique.
[1] [3] [5] [14] [16] Context Engineering in LLM-Based Agents | by Jin Tan Ruan, CSE Computer Science – ML Engineer | Medium
https://jtanruan.medium.com/context-engineering-in-llm-based-agents-d670d6b439bc
[2] [4] [48] [52] [53] [54] [55] Context Engineering – What it is, and techniques to consider — LlamaIndex – Build Knowledge Assistants over your Enterprise Data
https://www.llamaindex.ai/blog/context-engineering-what-it-is-and-techniques-to-consider
[6] [12] [20] [38] [43] [45] [46] [59] Building an enterprise AI knowledge base with RAG and Agentic AI
https://xenoss.io/blog/enterprise-knowledge-base-llm-rag-architecture
[7] [8] [10] [13] [36] [47] [61] Palantir’s AI-enabled Customer Service Engine | Palantir Blog
https://blog.palantir.com/a-better-conversation-palantir-cse-1-8c6fb00ba5be?gi=3bbd7d334fb0
[9] [17] [18] [23] [24] [25] [26] [29] [49] [58] Context Engineering
https://blog.langchain.com/context-engineering-for-agents/
[11] [15] [19] [34] [35] [50] Agent architectures
https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
[21] [22] [39] [40] AI Agents in Relational RAG: Simplifying Data Retrieval
https://www.akira.ai/blog/ai-agents-in-relational-rag
[27] [28] [31] [32] [37] GraphRAG and Agentic Architecture: Practical Experimentation with Neo4j and NeoConverse – Graph Database & Analytics
https://neo4j.com/blog/developer/graphrag-and-agentic-architecture-with-neoconverse/
[30] [33] [60] Enterprise Agentic Architecture and Design Patterns | Salesforce Architects
https://architect.salesforce.com/fundamentals/enterprise-agentic-architecture
[41] [42] [51] Why Shouldn’t Use RAG for Your AI Agents – And What To Use Instead : r/AI_Agents
[44] Chapter 1 — How to Build Accurate RAG Over Structured and Semi-structured Databases | by Madhukar Kumar | Software, AI and Marketing | Medium
[56] [57] [62] LLM Agent Evaluation: Assessing Tool Use, Task Completion, Agentic Reasoning, and More – Confident AI
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide